Sentiment Analysis.
Sentiment analysis could be viewed as one kind task in text classification. We can see many kind of applications in real life: movie review, google product search, bing shopping, twitter sentiment, market trends etc.
There are several affective states:
- emotion;
- mood;
- interpersonal stances;
- attitudes;
- personality traits.
Sentiment analysis is the detection of attitudes. It could be simple weighted polarity - positive/negative/neutral, also it could be a set of types with rank - like/love/hate/value/desire etc.
1. A Baseline Algorithm
A baseline algorithm could be a simple text classifier:
1.1 Tokenization
Since texts are unstructured data, we need to do many preprocessing, includes:
- deal with HTML/XML markup;
- twitter markup (names, hashtags);
- capitalization (preserve for words in all caps);
- phone numbers and dates;
- emoticons.
We can use regular expression or tokenizer in packages like nltk, sklearn, keras. There are many tools could automatically finish this, such as
1.2 Feature Extraction
In sentiment analysis, negation is important. we could add a NOT_ to every word between negation and following punctuation:
didn't like this movie, but I -> didn't NOT_like NOT_this NOT_movie, but I
We can also just use part of the text, e.g. only adjectives, use bag-of-words to convert each text into a vector.
1.3 Classification
This is the topic discussed in previous post: Stanford NLP (coursera) Notes (6). We can use Naive Bayes, SVM, Logistic Regression/Maximum Entropy Model, etc.
In practice it’s very easy to make texts hard to classify. Subtlety, Thwarted Expectations and Ordering Effects can easily make our model collapse. This is natural for NLP problems so don’t worry too much about it for now ;)
2. Sentiment Lexicons
Here are some collections of polarity lexicons:
- The General Inquirer
- LIWC - Linguistic Inquiry and Word Count
- MPQA Subjectivity Cues Lexicon
- Bing Liu Opinion Lexicon
- SentiWordNet
3. Learning Sentiment Lexicons
Semi-supervised learning of lexicons: we can just use a small amount of information, which contains a few labeled examples and a few hand-built patterns - adjectives conjoined by “and” have same polarity, adjectives conjoined by “but” have opposite polarity (Hatzivassiloglou and McKeown intuition for identifying word polarity), then bootstrap a lexicon. You can check the details of the learning process here.
- extract a phrasal lexicon from reviews
Extract two-word phrases with adjectives:
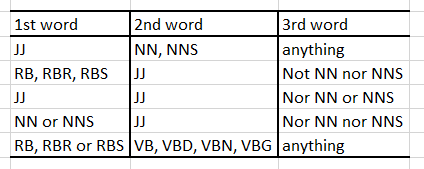
(If you’re not familiar with those tags you can check Penn Part of Speech Tags)
- learn polarity of each phrase
Positive phrases co-occur more with word “excellent”; negative phrases co-occur more with word “poor”. To measure co-occurrence, we can use pointwise mutual information, for two words
\[
PMI(w_1, w_2) = \log_2\frac{P(w_1, w_2)}{P(w_1)P(w_2)},
\]
to estimate them, use
\[
\hat{P}(w) = \frac{hits(word)}{N}, ~\hat{P}(w_1, w_2) = \frac{hits(w_1\text{ near }w_2)}{N^2}.
\]
Then the phrase polarity is
\[
\begin{aligned}
Polarity(phrase) &= PMI(phrase, \text{“excellent”}) - PMI(phrase, \text{“poor”}) \\
&= \log_2\frac{hits(phrase\text{ near “excellent”})hits(\text{“poor”})}{hits(phrase\text{ near “poor”})hits(\text{“excellent”})}.
\end{aligned}
\]
- rate a review by the average polarity of its phrases
Summary on learning lexicons:
Advantages: can be domain-specific; can be more robust with more words. The intuition is: start with a seed set of words (“good”, “excellent”, “poor”), find other words that have similar polarity by using “and”/“but”, or words that occur nearby, or WordNet synonyms and antonyms.