[Paper reading] Efficient Estimation of Word Representations in Vector Space.
1. Introduction
Word2Vec was first published in 2013, but the idea of word embeddings was presented much earlier. Back to 2003, Yoshua Bengio et al presented a Neural Network Language Model and word feature vectors were learned during the training (my previous note is the reading summary of this paper). That time the word feature vectors are just “By-product”, and the model didn’t attract too much attention - interesting to see how things changed over decades!
There are several papers related to Word2Vec, here I pick two of them:
- Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality arXiv:1310.4546
This time I’ll summarize the former one.
2. Highlights
Two new models are presented to learn word representations: Continuous Bag-of-Words (CBOW) and Skip-gram.
2.1 Introduction
Compared with other methods: Neural Nets perform better than LSA for preserving linear regularities; LDA is computationly expensive on large dataset.
2.2 Model Architecture
Figure from paper:
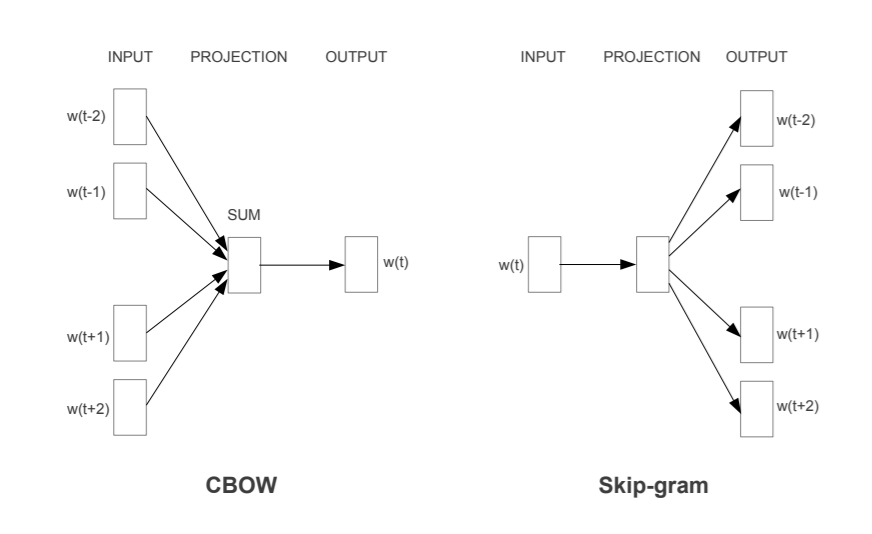
2.2.1 Continuous Bag-of-Words (CBOW)
CBOW will predict the current word \(w_{t}\) based on its context (history words and future words). The projection is simply a sum operation - add all word vectors of context. The order of words in the history won’t influence the projection.
As you can see, CBOW architecture is similar with the NNLM (Neural Nets Language Model) presented by Bengio et al. The difference is: non-linear hidden layer is removed (replaced with simply linear activation), projection layer shared for all words.
2.2.2 Skip-gram
Skip-gram will predict the context based on current word \(w_{t}\), therefore no sum operation in the projection. The range of the context need to be tuned. Set \(C\) as the maximum distance of the words, thus if \(C=5\), for eaching training word we will select randomly a number \(R\) between 1 and \(C\), then use \(R\) words from history and \(R\) words from the future of the current word as labels.
2.3 Conclusions
- When train high-dimension word vectors on a large amount of data, the resulting vectors can be used to answer subtle semantic relationships between words (such as city - country pairs)
- To measure the quality of word vectors, define 5 types of semantic questions (e.g. king - queen, brother - sister) and 9 types of syntactic questions (e.g. apparent - apparently, great - greater). Evaluate the overall accuracy
- To estimate the best choice of model architecture, evaluate models trained on subset of training data with vocabulary size restrict to most frequent 30000 words
- Increase word vector dimension and amount of training data together will get better accuracy
- CBOW works better than NNLM on syntactic tasks, about the same on semantic one; Skip-gram works slightly worse on syntactic task than CBOW (but still better than NNLM), and much better on semantic part of the test than all the other models
- Advantage of models: train high quality word vectors using very simple structure Neural Nets, reduce the computation complexity