Two important RNN structures
1. Introduction
It was one of the lectures of ECBM 4040 Deep Learning when I first knew RNN. I’ve used RNN like LSTM and GRU many times: course projects, kaggle competitions and work projects. They are both fundamental model structures for tasks require RNN or Sequence-to-Sequence (Seq2Seq) models, therefore this time I decide to briefly go over these two important RNN structures.
At the beginning I’d like to say thanks to colah’s blog, the style and structure are pretty clear, and the figures I use here are all from there.
2. RNN (Recurrent Neural Networks)
To deal with sequence data (time series, natural language), researchers proposed RNN which has a “time axis” in the network structure,
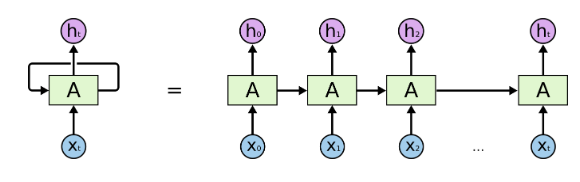
there is a input \(x\) for each timestamp, then it goes to hidden layers \(A\) and outputs \(h\). Then number of timestamps to use is a parameter, usually called max_length. For example data is a collection of sentences, then each word (timestamp) is a input \(x\), sentences with length smaller than max_length will be padded some number (e.g. 0) and sentences with length larger than max_length will be truncated, therefore finally all samples have same length of input.
A simple feedfoward step will be
\[
a_{t} = \tanh\left(W\left[a_{t-1}, x_{t}\right] + b\right),
\]
here \(a_{t}\) is the output of current hidden layers, \(a_{t-1}\) is the output of previous one hidden layers , \(\tanh()\) is the activation function (which could have many options), \(x_{t}\) is the input at current timestamp; \(W\) and \(b\) are trainable parameters.
But vanilla RNN performs bad on long inputs which require more information in the past to be extracted, in other words it is not able to capture “long-term dependecies”.
3. Gradient Vanishing
The issue of losing long-term dependecies is from gradient vanishing. This is a common problem for back-propagation in deep neural networks, the gradients gradually vanish when it back propagate to earlier timestamps. For strict mathematical reasoning you could refer to CS224n: Natural Language Processing with Deep Learning Lecture Notes at part V. Another issue in training neural networks is gradient explosion which could be solved using gradient clipping. However, grading vanishing is harder to solve. But one of the solutions is using LSTM.
4. LSTM
The LSTM is proposed to avoid the gradient vanishing problem to capture long-term dependency.
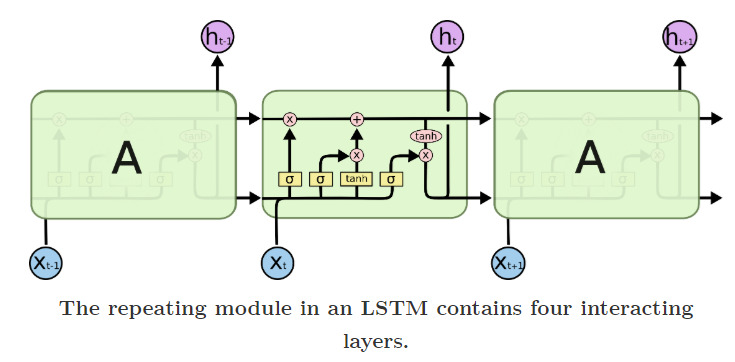
Compared with vanilla RNN, LSTM has an extra component called cell state \(C_{t}\) (used to “memory”), along with regular hidden states \(h_{t}\).
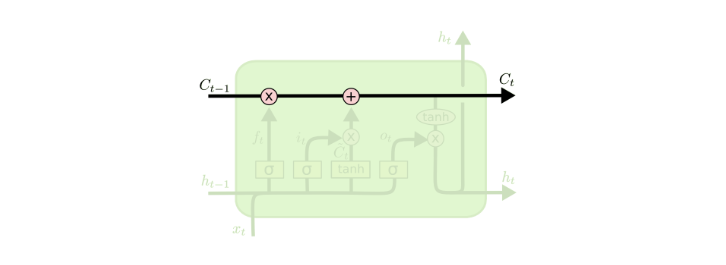
Information will be either add to or remove from the cell state, it is controlled by the gates. LSTM contains three gates: forget gate, update gate and output gate.
4.1 Forget gate
First step is go through forget gate.
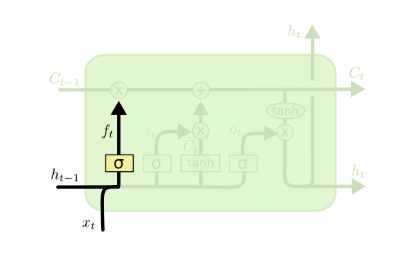
it is a simple layer with sigmoid activation:
\[
f_{t} = \sigma\left(W_{f}\left[h_{t-1}, x_{t}\right] + b_{f}\right)
\]
\(f_{t}\) will be a value between 0 and 1, indicate the proportion to “keep” the information, therefore larger \(f_{t}\) means “forget” less.
4.2 Update gate
Second step is go through update gate.
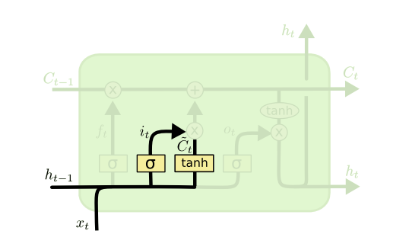
it contains two steps:
- a sigmoid layer to indicate the proportion to update
- a \(\tanh\) layer to create new value
therefore:
\[
i_{t} = \sigma\left(W_{i}\left[h_{t-1}, x_{t}\right] + b_{i}\right) \\
\tilde{C_{t}} = \tanh\left(W_{C}\left[h_{t-1}, x_{t}\right] + b_{C}\right)
\]
\(i_{t}\) is a value between 0 and 1 to apply on \(\tilde{C_{t}}\), then the value will be added into cell state,
\[
C_{t} = f_{t}C_{t-1} + i_{t}\tilde{C_{t}}.
\]
4.3 Output gate
Finally it’s the output gate.
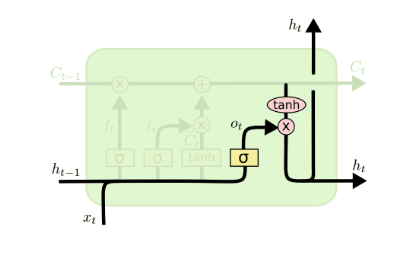
with,
\[
o_{t} = \sigma\left(W_{o}\left[h_{t-1}, x_{t}\right] + b_{o}\right) \\
h_{t} = o_{t}\tanh(C_{t})
\]
therefore \(o_{t}\) determines the proportion to output (hidden state).
5. GRU
GRU (Gated Recurrent Unit) is a simplification of LSTM. It combines the forget gate and update gate in LSTM to a single update gate and it also combines cell state and hidden state.
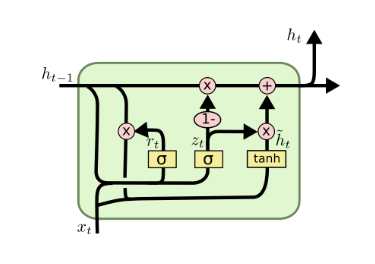
As a simplification version, GRU is supposed to perform better on less data and behave like what other simplification version models do on specific cases. TO BE CONTINUED…
6. Summary
- Gates
Compared with vanilla RNN, LSTM maintains a memory cell at each timestamp. The memory is updated by partially forgetting existing memory (forget gate, therefore prevent gradient vanishing) and adding new memory (update gate). In this way, LSTM enables capture information from sequence at early stage and carries the information over a long distance (long distance dependencies).
- Gradient Vanishing Problem
There are several nice papers to show why LSTM could avoid gradient vanishing problem. In short, LSTM introduces gates to control, which is different from vanilla RNN, this is the reason why gradient vanishing is prevented.
7. References
- Colah’s blog,
- Stanford CS224n Notes,
- Coursera Notes,