[Paper reading] Wide & Deep Learning for Recommender Systems.
This paper presents a new framework for recommandation tasks, which combines the advantages of two different type of models:
- Generalized Linear Models (logistic regression): efficient for large scale regression and classification tasks with sparse data, provide nice interpretations;
- Deep Neural Networks: extract more complicate feature interactions and less feature engineering.
1. Introduction
Recommender systems can be viewed as search & ranking system, where the inputs are queries with set of of user and contextual information and outputs are ranked list of items. One of the challenges in recommender systems is to achieve both memorization and generalization.
Memorization is loosely defined as learning the frequent co-occurrence of items or features, exploiting the correlations in historical data. Recommendations based on memorization are more topical and directly relevant to the items on which user have already performed actions. Therefore you’ll not expect recommendations that surprise you. Memorization could be achieved by effectively using cross-production transformations over sparse features, a.k.a feature interactions. But it doesn’t generalize to query-item feature pairs that have not appeared in historical data.
Generalization is based on transitivity of correlation and explores new feature combinations that have never seen before or rarely occurred. Recommendations based on generalization tend to provide more diverse results. Embedding-based models such as factorization machines or deep neural networks can achieve this by learning a low dimensional dense embedding vector for each query and item feature. But this could be difficult to learn effectively for queries and items when the underlying query-item matrix is sparse and high-rank, users with specific preferences or niche items ith a narrow appeal.
This paper shows that the Wide & Deep framework significantly improves the app acquisition rate on mobile app store while satisfying the training and serving speed requirements.
2. Recommender Systems Overview
Overview of recommender systems:
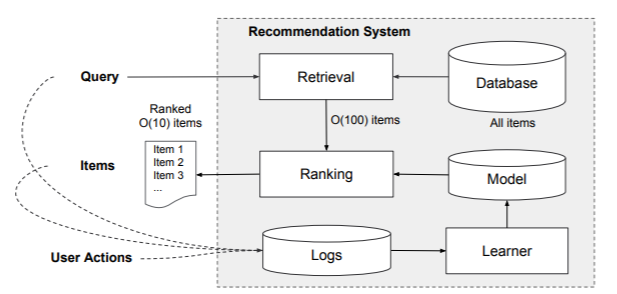
A query which contains user and contextual features is generated when a user visits. The recommender system returns a list of items (also referred to as impressions) on which users can perform actions such as click or purchase. These actions along with queries and impressions are recorded in the logs as the training data for the model.
Since in real business case, the amount of items is huge therefore the first step upon receiving a query is retrieval, the retrieval system returns a short list of items that best match the query using various signals. After reducing the candidate pool, the ranking system ranks all items by their scores, usually \(P(y|\mathbf{x})\) - the probability of a user action label \(y\) given the feature \(\mathbf{x}\), including
- user features: country, language, demographics;
- contextual features: device, hour of the day, day of the week;
- impression features: app age, historical statistics of an app.
This paper will focus on the ranking model.
3. Wide & Deep Learning
3.1 The Wide Component
The wide component is a generalized linear model of form \(y=\mathbf{w}^{\top}\mathbf{x} + b\). One of the most important part in features \(\mathbf{x}\) is the cross-product transformation, a.k.a feature interaction, it captures the interactions between one-hot binary features and adds non-linearity to the model.
3.2 The Deep Component
The deep component is a feed-forward nerual network. The high dimensional categorical features are first convert into a low dimensional and dense real-valued vector, often referred as embeddings. The embedding vectors are initialized randomly and then the values are trained to minimize the final loss function. Then they are fed into the hidden layers with feed forward step
\[
a^{(l+1)} = f(W^{(l)}a^{(l)} + b^{(l)}),
\]
where \(l\) is the layer number and \(f\) is the activation function.
3.3 Joint Training of Wide & Deep Model
Combined them together with a weighted sum of their output log odds as the prediction, which is then fed to one common logistic loss function for joint training:
\[
P(y=1|\mathbf{x}) = \sigma\left(\mathbf{w}^{\top}_{\text{wide}}\mathbf{x} + \mathbf{w}^{\top}_{\text{deep}}a^{(l_{f})} + b\right).
\]
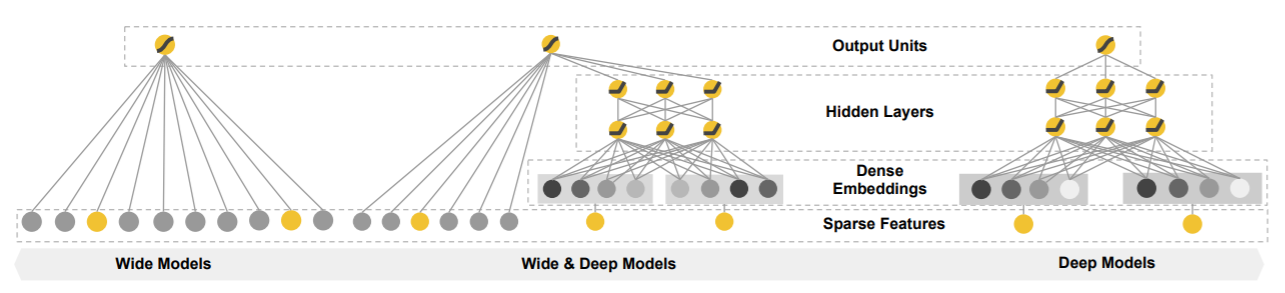
In experiments, FTRL algorithm with L1 regularization is used to train wide part and AdaGrad is used for deep part.
4. System Implementation
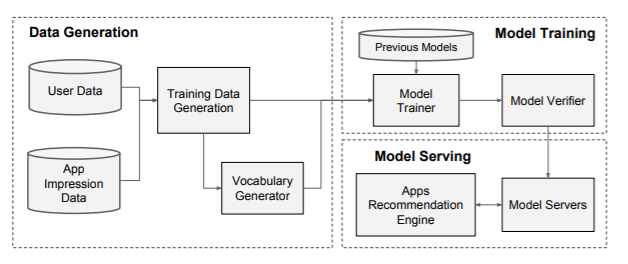
The implement of the apps recommendation pipeline consists of three stages: data generation, model training and model serving as shown follows:
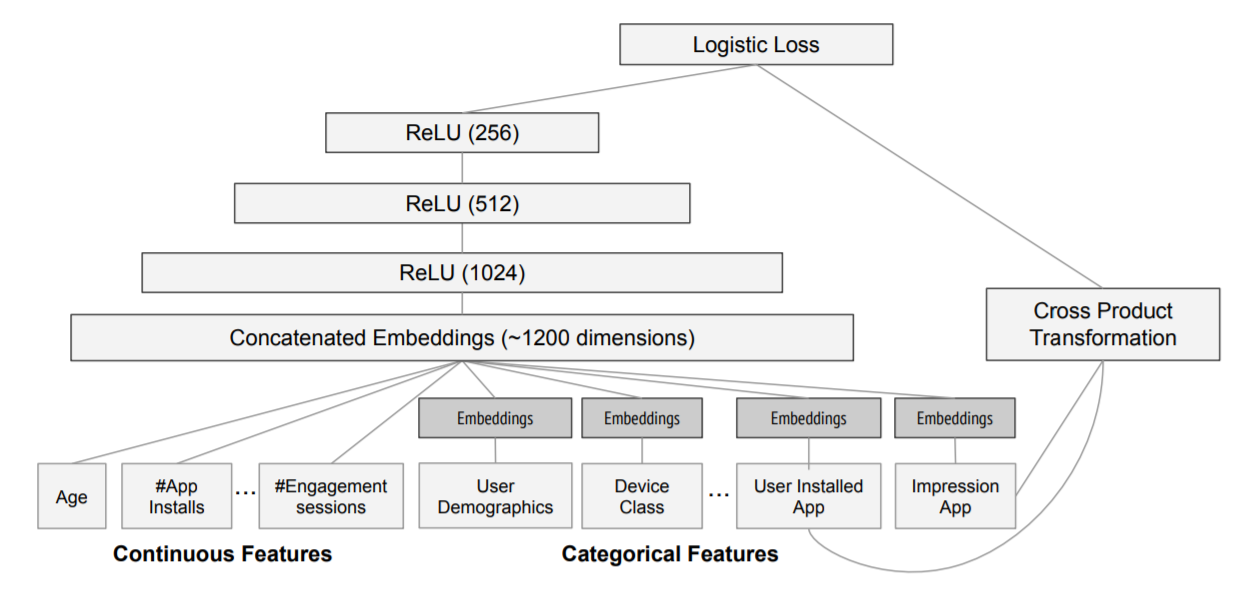
And the model structure used for experiements is:
5. Experiments and Conclustions
A live online experiment is conducted in an A / B testing framework for 3 weeks. For the control group, 1% of the users were randomly selected and presented with recommendations generated by a high-optimized logistic regression with rich cross-product feature transformations. For the experiment group, 1% of the users were randomly selected and presented with recommendations generated by Wide & Deep model. Wide & Deep model improves the acquisition rate on the main landing page of the app store by 3.9% relative to the control group, which is statistically significant. The results were also compared with another 1% group using only the deep part of the model with same features and neural network structure, the Wide & Deep model had 1% gain on top the deep model, which is also statistical significant.
In summary, memorization and generalization are both important for recommender systems. Wide models can effectively memorize sparse feature interactions using cross-product transformation, while deep models can generalize to previously unseen feature interactions through low dimensional embeddings. The Wide & Deep model combine the strengths of both types of the model, and online experiments showed that it let to significant improvement on app acquisitions over previous models.