Introduction to AB Testing.
1. Concepts
1.1 What is AB Testing
AB testing is a general methodology used online when need to test out new products or new features. Basically it takes two sets of users, show the control set with existing product / feature, and experiment set with new version. And observe how do these users respond differently, finally determine which version is better.
1.2 What to test
There are variety of things to test:
- visible changes: new features, new additions to UI, ranking list, different look of the website;
- invisible changes: page load time, new recommendation algorithms.
However there are also things that AB testing is not able to test. AB testing isn’t useful in testing out new experience:
- user who don’t like change too much would prefer old version;
- user will feel excited and test out everything (novelty effect).
The issues of using AB testing in these cases include:
- AB testing needs baseline - here it is hard to define
- AB testing cannot run forever - here it is hard to know when to stop
1.3 What are Complimentary for AB Testing
- Retrospective Analysis
- User Experience Research
- Focus Group
- Surverys
2. One Example
2.1 Background
Audacity is a company provides online finance courses. The user flow of Audacity, i.e. user behaviors on Audacity website, could includes these:
- Homepage visit
- Explore site (click pages and view more details)
- Create user account
- Complete courses
The number of events is decreasing from top to the bottom, which is also know as customer funnel.
Experiment (test the hypothesis): there is a new feature - whether changing the “Start Now” button color from orange to pink will increase more users explore the website.
2.2 Metrics
There are multiple selections to measure the level of user engagement on website:
- total number of courses complete
- total number of clicks
- click-through rate (total number of clicks / total number of pageviews)
- click-through probability (unique user who clicks / unique user who visits page)
Here click-through probability is selected. And the hypothesis could be more specific: whether changing the “Start Now” button color from orange to pink will increase the click-through probability.
In general, use a rate metric when you want to measure the usability of the website; use probability metric when you want to measure the total impact of the change.
2.3 Hypothesis Test
Here the statistical hypothesis test part (distribution of metrics, confidence intervals, statistical significance, null / alternative hypothesis, standard error) is skipped.
In real world, statistical hypothesis test is just the first step. After this, more people will involved to determine what is the practically significance.
2.4 Size and Power (Trade-Off)
Before running test, we need to decide when to stop the test, i.e. how many pageviews required in order to get statistical significant (statistical power). Here is the trade-off: the smaller change we want to detect, the larger samples we need to get, hence increase the time to collect data.
2.5 Confidence Interval Analysis
Here is the list of possible confidence interval versus the significance level (solid line is 0),
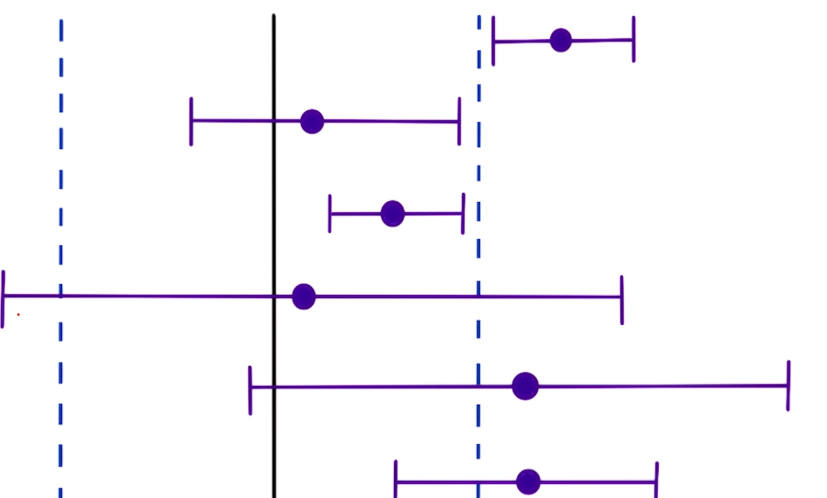
Recommendations for conclusions:
- the change is significant, it is helpful to add the new change
- the change is not significant, since it overlaps with 0
- the change is helpful but not significant enough
- better to run new test
- better to run new test
- better to run new test
How to make decisions if no time to run new test? Usually ask the decision maker, be aware to take the risk because the data is uncertain; or use other factors besides the data.