Information Retrieval Basis.
1. Introduction
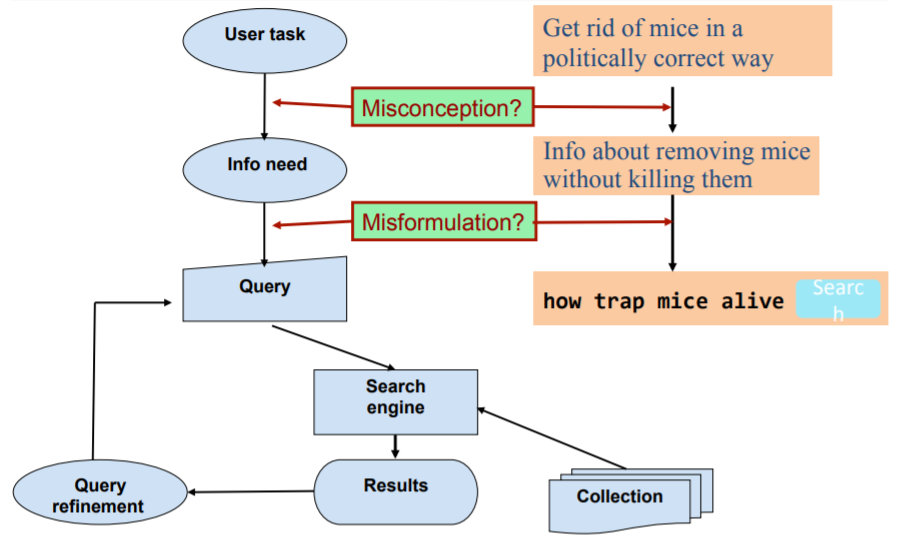
Information Retrieval (IR) is finding materials (documents) of an unstructured nature (text) that satisfies an information need from large collections. As highlighted here, the goal is retrieved documents should be relevant to the user’s information need and helps the user complete tasks.
Classic search model in Information Retrieval system, the information need will be translated into query, and the model should be able to translate the query into information need.
The evaluation metrics for Information Retrieval system include Precision and Recall, which are very commonly used in Machine Learning; other metrics include Mean Average Precision, etc.
2. Term-Document Incidence Matrices
An important idea in Information Retrieval is ranking. Linear search won’t be able to rank the results.
Term-Document incidence matrices is a data structure where terms are in rows and documents are in columns, given there are \(M\) terms and \(N\) documents, the matrix will have size \(M\times N\). The value in the matrix can be boolean (0/1), or count (non-negative integers), or TFIDF weights.
One issue in using this type of matrix is storage. Given the huge amount of information, the matrix will be very sparse, therefore a better storage is storing the position of non-zero values.
3. Inverted Index
Inverted Index is a key data structure underlying modern IR. Using inverted index, each term will store a list of documents (document ID) contain the term, the list size is not fixed. Specifically, the term is called dictionary, the list of document ID is called Postings. To create the index, the raw document (text) will go through several preprocessing steps:
- tokenization (cut sequence of text into tokens)
- text normalization
- stemming
- stopwords removal
- …
Then it will create results like
|
|
and merge document ID into posting lists. The terms and document ID will be sorted.
4. Query Processing with Inverted Index
Suppose a standard query is searching term A and B: A and B, the system will then return the merged list from the posting list of A and B, the merge can be done in linear time since the document ID are sorted, suppose the size of posting lists are \(x\) and \(y\), the time complexity is \(O(x + y)\).
5. Phrase Queries and Positional Indexes
If the queries contains phrases, then the previous index won’t work. There are two other indexes available: Biword Index and Positional Index.
Biword index is very easy to generate false positive results and it will also blow up due to bigger dictionary.
Positional index will adjust the posting list by adding the position of the term: term: [doc_1 (position_1, position_2), doc_2 (...)]. Positional index can deal with proximity queries while biword index cannot; it will also expand the storage, however given its usefulness in phrase and proximity queries it is still good.
These two methods can be combined.